OpenID and Identity Services
In response to my previous blog post about identity services, I received the following question from Billy:
“isn’t this what OpenID aims to do? If not, how not?”
![]() OpenID can be a small (but key) part of the identity services story. The main problem that OpenID tries to solve is one that most people who use the internet extensively face – that of too many usernames and passwords. Instead of having to remember a username/password combo for each website I interact with (Google, Yahoo, Flickr, Magnolia, banking websites, blogs, etc), I can set up and use a single OpenID account at all those websites instead. OpenID also hopes to provide a number of technological advantages to the whole authentication experience by figuring out ways to prevent phishing and pharming attacks.
OpenID can be a small (but key) part of the identity services story. The main problem that OpenID tries to solve is one that most people who use the internet extensively face – that of too many usernames and passwords. Instead of having to remember a username/password combo for each website I interact with (Google, Yahoo, Flickr, Magnolia, banking websites, blogs, etc), I can set up and use a single OpenID account at all those websites instead. OpenID also hopes to provide a number of technological advantages to the whole authentication experience by figuring out ways to prevent phishing and pharming attacks.
So OpenID’s main aim is at providing a secure, scalable solution for the authentication service in the identity stack (see below for the latest diagram of the identity services stack, or read our whitepaper on the subject). To a lesser extent, it also hopes to help the identity provider and authorization services by becoming a transport container for identity claims that drive these services.
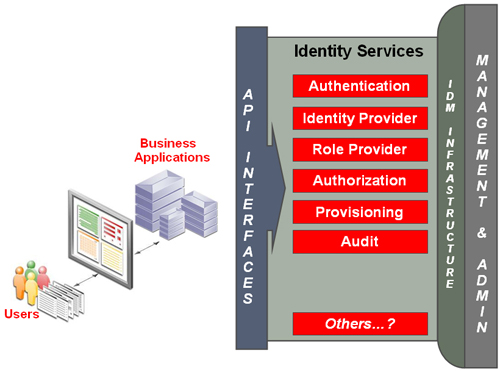
Identity Services Stack
The vision for identity services has always been that applications should use only those services that they need, and not be forced to use every single service. So simple web applications with minimal needs could get away with simply supporting OpenID. But that should not be confused with not requiring a full-fledged identity services infrastructure where appropriate.
At present there are nearly 14,000 OpenID enabled websites (http://janrain.com/blog/2008/05/). Most are user generated content sites – wikis, blogs, discussion groups, social networks, etc. Further, there are nearly 400 million OpenID enabled users, although many of these are not active or may not even know that they have an OpenID since they were passively provisioned by the likes of AOL and Yahoo.
We are starting to see OpenID expand into more mainstream applications such as media (CNN Political Market), group productivity applications (37 Signals), and business contact management (Plaxo).
What is required for the acceleration of OpenID adoption will be easier deployment models for website operators and more intuitive end user tools. One example of this is a recently released OpenID login widget, ID Selector (wwww.idselector.com).
The OpenID Foundation and the companies supporting OpenID (Yahoo, Microsoft, AOL, Google, IBM, BBC, Verisign, JanRain, France Telecom, etc.) also continue to promote adoption of OpenID while enhancing the associated products and services.
As the dialog continues, we’ll learn more about when and where OpenID-based solutions can address market needs.